
Artificial intelligence is only as good as the people who create it. This is true not only for the algorithm, but the inspection data that helps train it.
Sewer inspection AI training requires inspection media to be thoroughly and accurately labeled. Developers use this labeled media to teach AI what to look for during automatic defect coding. But what happens when a pipe defect is too ambiguous for even experienced sewer pros to code with 100% accuracy? Do the professionals correcting the AI introduce subjectivity?
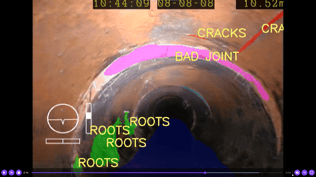
Subjectivity affects us when decisions are influenced by personal feelings, tastes, or opinions. The absence of subjectivity is often cited as a benefit of technology: Computers make their "decisions" based on pure facts.
In reality, however, developers accidentally introduce bias and subjectivity into many computer systems, including while training AI. Even if the majority of the defects labeled in training media is accurate, the incorrect labels that sneak through the QA/QC process can taint the AI’s accuracy.
AI developers work hard to identify and prevent these biases so that their systems see more accurate, reliable results. And in the case of Sewermatics, successfully countering bias requires tapping years of experience from a full team of wastewater professionals.
Pinpointing Corner Cases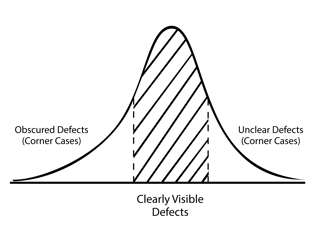
When inspecting sewer systems, even the best operators will eventually encounter defects they just can’t make out. These unclear defects that occur outside of the average are called “corner cases''. In sewer inspection AI, corner cases are defects that cause debate among coders. They don’t generally appear in the majority of sewer data, so when they do, it’s because of qualities that set them outside of the average bell curve.
A corner case might be a large crack that borders on a fracture, or a dark spot that looks like a crack to one operator but a root to another. These discrepancies need to be resolved before the labeled inspection media is fed to the AI during the training process. If mistakes are repeatedly fed to the AI, machine learning tells us that those errors could spoil the accuracy of future results. However, we can correct these biases before they affect the AI engine by changing how we label our inspection media.
Overcoming Subjectivity and Bias in AI With Collective Knowledge
To overcome these biases, many AI developers are refocusing efforts from training methods that prioritize quantity of training media to bias-correcting practices that prioritize quality. By bringing together a full team of certified sewer professionals, as WinCan has done to support Sewermatics, AI teams are using their collective knowledge to prevent trainer bias from impacting data. This cuts off AI bias at the source, allowing the AI to more accurately process corner cases that show up in sewer inspections.
In many ways, this practice is about overcoming the subjectivity inherent in AI training. AI can’t understand the context (composition, lighting, resolution, etc.) of images the way humans can. So it’s up to human developers to ensure AI has enough context to identify and support the analysis of corner cases.
Trending Toward Better Data Labeling
As AI reveals new capabilities for sewer teams and poses new challenges for developers, the future of AI in the wastewater industry grows even brighter. Like all new technologies, AI entered the sewer world with its own learning curve, and with so much data at stake, addressing broader trends in operator bias is essential at this stage of development.
While subjectivity affects all AI engines, WinCan’s Sewermatics has built its team to tackle subjectivity at the source. By pooling the collective knowledge of NASSCO-certified sewer professionals from every walk of life, corner cases are quickly identified, context is added to labeled datasets, and WinCan AI continues to get faster and more accurate. See WinCan AI for yourself by scheduling a free Sewermatics consultation:




